Основатель «Школы траблшутеров» Олег Брагинский и ученица Марина Строева проверят чат-сервис на прочность: от учёта железа и HTTP-baseline до жёсткого soak-сценария. Выявят пределы системы, причины сбоев и зоны улучшения перед ожидаемым приростом аудитории.

В системе несколько независимых Go-бекендов общаются между собой через HTTP, синхронизируя присутствие пользователей, маршрутизацию звонков и доставку сообщений. Каждый отдельный инстанс с собственной Postgres, SFU MediaSoup и event–bus для real–time соединений клиентов.
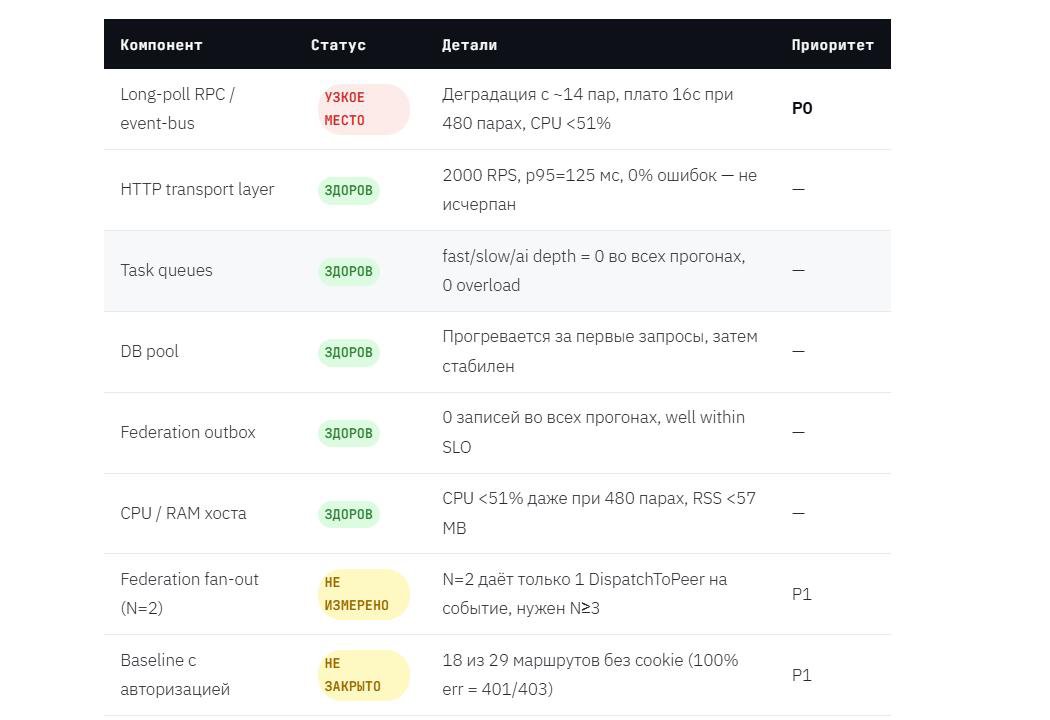
Главный архитектурный риск федерации: при росте числа серверов (N) трафик масштабируется как O(N−1) на каждое событие присутствия. Одно сообщение «пользователь онлайн» порождает N−1 исходящих HTTP-вызовов DispatchToPeer. При N=100 одно событие = 99 запросов к соседям.

Цель нагрузочного тестирования – понять при каких N и интенсивности событий система выходит за SLO, и где именно находится бутылочное горлышко вне зависимости от федерации: в HTTP–слое, очередях задач или механизме real–time доставки событий клиентам.

План работы строился по принципу замкнутого контура: каждый прогон обязан завершаться числовым артефактом без пустых ячеек. Тестирование разбито на четыре независимых слоя, каждый из которых отвечает на отдельный вопрос. Характеристики стенда состоянии покоя:

Конфигурация используемых инстансов:

Генератор разобрал регистрацию маршрутов в app.go и построил каталог из 30 строк. Каждый маршрут получил 20 запросов при конкурентности 6 (session_cookie_set: false). Результаты идентичны для msk и cerna.

18 маршрутов с err=100% работают корректно. Возвращают 401/403/404 на запросы без авторизации. Ожидаемое верное поведение. Следующий шаг – прогон с пулом тестовых сессионных cookie для измерения реальной производительности этих эндпоинтов под нагрузкой.
Характерный паттерн задержек: /healthz показывает p95=376 мс при первых запросах из-за прогрева connection pool Postgres (cold start). Все остальные рабочие маршруты стабильно укладываются в 122–124 мс – латентность одного round–trip через localhost + запрос к Postgres.
Пропускная способность 2’000 RPS без единой ошибки. Ступенчатый ramp на GET /healthz с шагами 50, 100, 200, 350, 500, 800, 1’200, 1’600, 2’000 RPS. Длительность каждого шага 4–5 секунд. Оба региона тестировались параллельно и показали практически идентичные результаты.

На графике задержка падает при росте нагрузки. Это классический эффект прогрева connection pool: первые запросы при 50–100 RPS устанавливают новые соединения с Postgres (latency >300 мс), после чего пул прогревается и операции идут по готовым соединениям (latency около 120 мс). При 500+ RPS pool полностью заполнен, задержка стабилизируется на уровне 125–132 мс.

Итог: инфраструктурный слой (HTTP transport + Go runtime) здоров. Оба инстанса уверенно держат 2’000 RPS с p95=125 мс и нулевыми ошибками. Ресурс сервера по transport-слою не исчерпан: прогон остановлен потолком чартера, а не деградацией.
Тестируем реальный сценарий: регистрация – сообщение – чтение. Мягкий ramp–тест: старт с 4 пар воркеров, +2 пары каждые 12 секунд, лимит 64 пары. Каждая пара воркеров – два аккаунта, выполняющих полный цикл «быстрая регистрация – send_message – чтение через API» с задержкой между циклами. Прогон снимался параллельно с SSH–сэмплером CPU хоста.

Ключевое наблюдение: SLO по RPC (500 мс) нарушается уже примерно при 12–14 парах (24–28 пользователях) – задолго до того, как CPU приближается к насыщению. К финалу прогона (52 пары) RPC достигает 1’671 мс при CPU всего около 30%.
RPC – узкое место, независимое от CPU. Бутылочное горлышко находится в механизме long–poll, а не в вычислительных ресурсах. Увеличение числа ядер или RAM ситуацию не исправит.
Агрессивный soak–тест: старт с 12 пар, +12 пар каждые 9 секунд, лимит 480 пар (960 условных пользователей), задержка между циклами 100 мс. Цель – намеренно вывести систему в зону деградации и зафиксировать характер отказа.

Агрессивный soak – RPC hint при нарастании нагрузки: RPC больше 5’000 мс (критично), RPC 2’000–5’000 мс (плохо), RPC 1’000–2’000 мс (тревога), RPC меньше 1’000 мс (терпимо). Два чётких порога деградации:
- ПОРОГ 1: больше 1 секунды
- ПОРОГ 2: больше 3 секунд, лавинообразный рост

Несмотря на RPC в 16 секунд, цикл «отправить–получить» завершается без ошибок. Это graceful degradation: сервер технически справляется, но субъективное качество полностью исчезает, пользователь видит «вечно ждущий» мессенджер, хотя с точки зрения сервера всё в порядке.
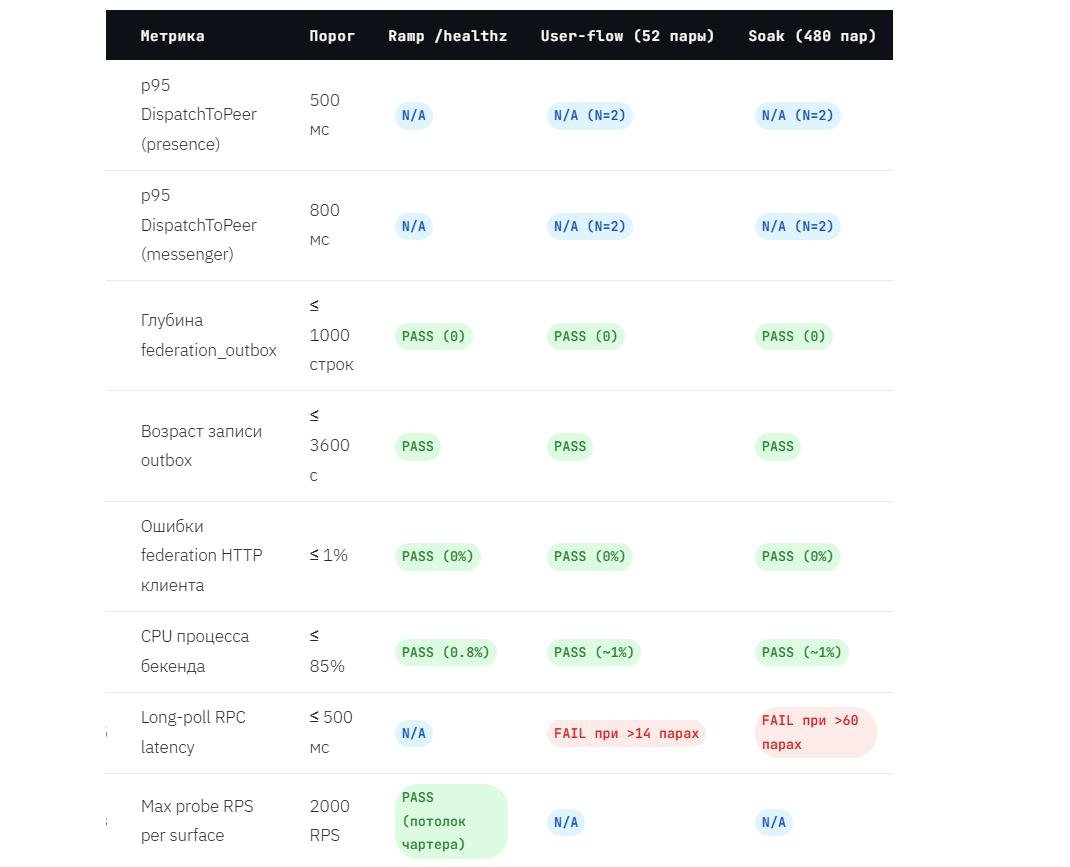
Единственное нарушение SLO. RPC–задержка (rpc_poll_ms_hint) пробивает порог 500 мс уже при 14 парах (28 пользователях) в мягком ramp–тесте и при 60 парах (120 пользователях) в агрессивном soak–тесте. Все остальные SLO из чартера выполнены с запасом во всех прогонах.

Long–poll RPC оказалось главное узкое место. Все четыре прогона указывают на одно и то же: long–poll механизм не масштабируется с ростом числа параллельных соединений. При этом CPU хоста остаётся ниже 51% даже при 480 парах – процессор практически не задействован.
При одинаковом числе пар агрессивный тест показывает существенно более высокие задержки. Нагрузка накапливается: при быстром темпе добавления пар event–bus не успевает разгрузить очередь соединений между шагами. Система не достигает steady state.
Система деградирует без явного отказа. Ни переполнения очередей задач, ни паник горутин, ни превышения лимитов БД. Все 45’716 циклов soak–теста завершены успешно. Что хорошо с точки зрения надёжности, но затрудняет диагностику в продакшене – мониторинг может не заметить проблему, пока пользователи не начнут жаловаться.
p95=376–385 мс при первых запросах к /healthz – не деградация, а прогрев. После установки пула из 20 соединений (idle→active: с 5 до 20 при msk) задержки падают до стабильных 122–125 мс. Важно не интерпретировать cold–start latency как ухудшение производительности под нагрузкой.
Итоговые числа прогона:
- Около 24–28 пользователей до нарушения SLO RPC, По мягкому ramp–тесту
- Около 120 пользователей до RPC больше 500 мс по агрессивному soak
- 2’000 RPS, Пропускная способность HTTP, p95=125 мс, 0% ошибок
- Меньше 51% макс. CPU busy (хост), при 480 парах, i9–12’900K
- 0 нарушений SLO federation, outbox, err%, DispatchToPeer
- 0 циклов с ошибками из 52’051 всего
Long–poll блокирующее соединение, которое удерживает горутину на всё время ожидания события. При 480 парах это 960+ одновременно заблокированных горутин плюс необходимость fan–out каждого события на все из них. Для решения придётся:
- добавить connection limit per instance с балансировкой на уровне L7
- измерять глубину очереди event–bus и размер буфера под нагрузкой
- перейти с long–poll на WebSocket с явным управлением backpressure
- профилировать с pprof под нагрузкой 200+ пар – найти hotspot в runtime горутин.
Главный вывод.
Инфраструктурный слой (HTTP, Postgres, task queues, federation outbox) здоров и не является ограничением. Единственное реальное узкое место – long–poll event–bus, который деградирует независимо от CPU начиная примерно со 120 одновременных пользователей.
На железе i9–12’900K, 24 ядра – система корректна до 960 условных пользователей без единой ошибки приложения, но с задержками RPC до 16 секунд. Путь к масштабированию лежит через рефакторинг механизма real–time доставки событий, а не через добавление железа.